周末,客户反馈了一个页面上的组件操作卡顿的问题,周一抽空看了一下,发现这个问题虽然不复杂,但里面挺有门道,顺手记录一下。
这个控件用于客户搜索供应商厂家,数据陆陆续续添加的比较多,现在已有上千条不同的厂家数据,长的大概类似这样:

控件中的搜索功能,支持使用文字的简拼和全拼进行搜索,底层实现了一个名为
toPinYin 的函数,用于将汉字转换为拼音码。这个转换功能是在前端实现的。问题分析
其实这种问题产生的原因较为明确:由于数据量较大,前端搜索时需要进行大量计算,从而导致卡顿。
从
Performance 性能面板可以看出,由于 toPinYin 函数执行时间过长,导致浏览器出现明显的掉帧(即 FPS 降为 0):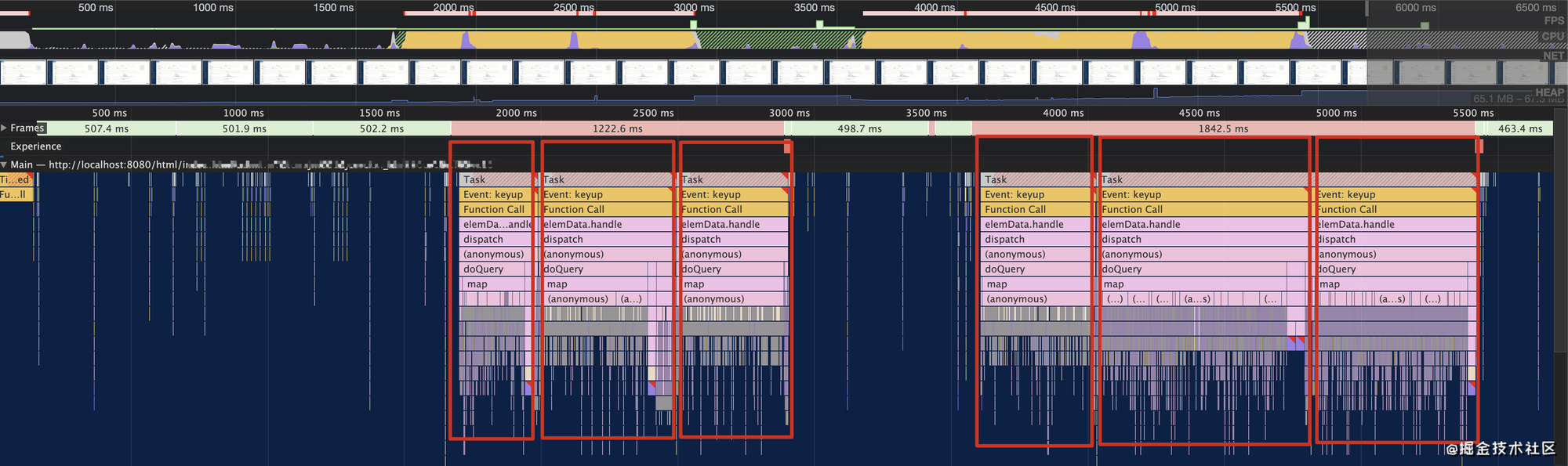
该次测试中,在下拉输入框中快速输入
“ydl”,然后再将文字内容快速删除,可以看到页面出现了累计接近 3s 的长任务,导致页面卡顿。解决方案
1. 函数防抖
针对此类问题,首先常见的解决方案是为输入框增加防抖,避免每次输入都触发重查询。直接使用
lodash 提供的 debounce 方法增加防抖后,重新测试: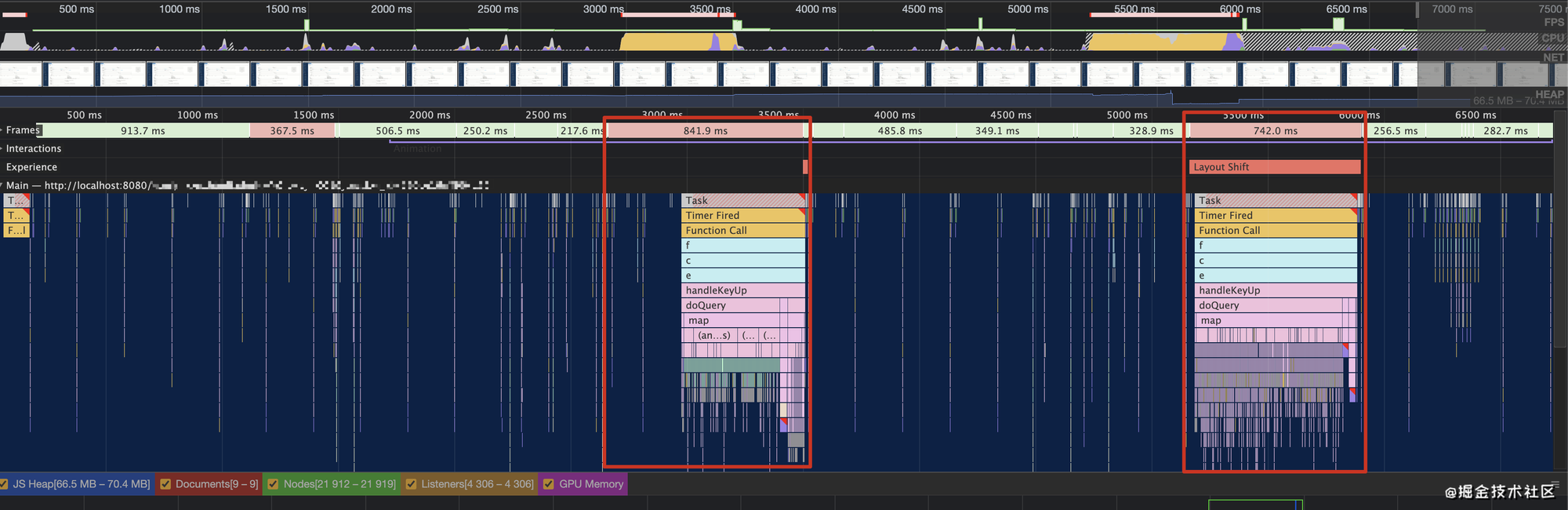
可以看出,通过增加防抖函数,可以将重查询压缩在一次函数值行内完成,在快速输入的场景下,页面卡顿时长由 3s 下降到了 1s 左右。
不过,防抖函数并不能很好的应对慢速输入的场景(即“逐字输入”)。在输入框中慢速输入
“ydl” 后,观察性能面板可以看出,虽然每次卡顿时间不长,但累计阻塞时间同样在 3~4s 左右。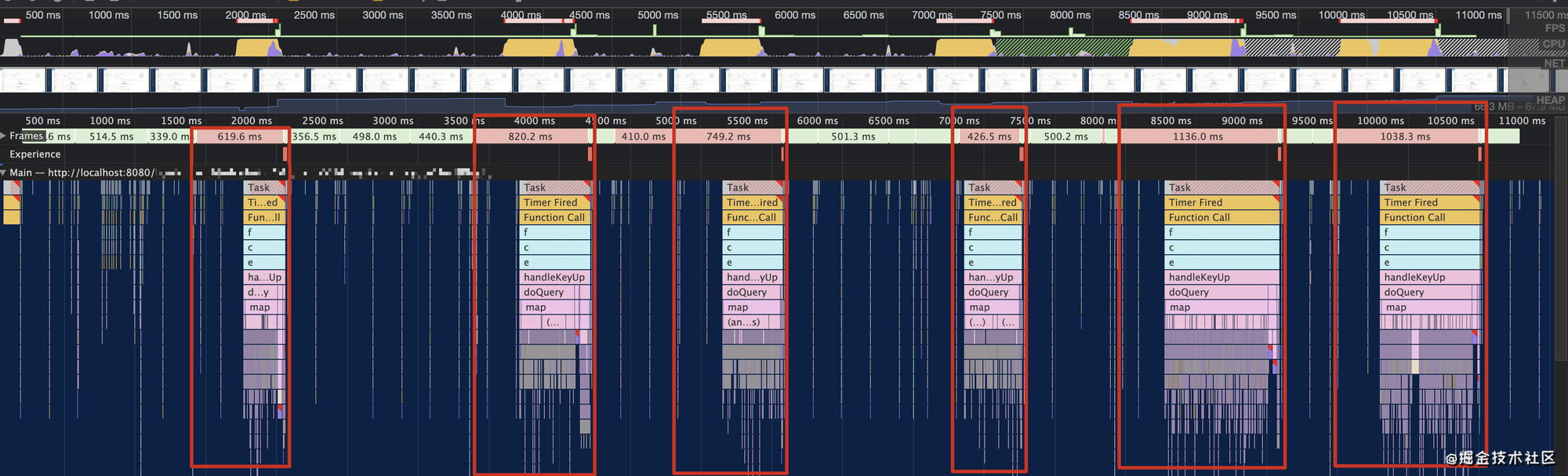
2. 前端缓存
通过分析该处的业务可知,该处的文字搜索是在既定的范围内搜索的,那么可以通过增加缓存,来减少函数反复执行的开销。

可以看出,首次执行时,阻塞时间仍接近仅加上防抖函数时的 1s 左右,后续连续多次输入、删除文字时,函数开销明显下降。
实际上,分析
toPinYin 函数可以看出,该函数底层维护了一个很大的常用字到拼音码的映射表,每次调用函数时,都会生成一个很大 JS 对象,在调用结束伴有 GC,说明该函数需要优化。
两种缓存策略
Map缓存
一种常用的缓存方式就是使用 es6 的
Map 对象:const cache = new Map(); function toPinYin(input) { if (cache.has(input) return cache.get(input); ... if (!cache.has(input)) { cache.set(...); } return ... }
- LRU 缓存
另一种常用的缓存形式是使用了 LRU 算法的缓存策略,其实这里的场景非常适合 LRU 算法。由于汉字的字形非常多,当系统运行一段时间后,Cache 的量可能显著增长,但不能被 GC 释放,从而显著增加 GC 开销。
而常用汉字数量是有限的(通常认为是 8500 个),根据 2-8 定律,最常用的汉字不会超过
8500 * 0.2 = 1700 个,根据此指定 LRU 缓存上限为 2500,既能很好的提升运行效率,也不会造成缓存无限增长。3. 优化算法
由于现在汉字使用的普遍为
UTF-8 编码,而 Unicode 天然具有顺序性,可以通过浏览器的 Intl 对象构造汉字排序函数,从而通过二分法之类的查找算法在字库中搜索,避免每次都需要遍历整个字库对象。这一功能 tiny-pinyin 已经实现,通过引入 tiny-pinyin 后,可以使用其提供的解析函数来替代原有的函数功能。

可以看出,单次无缓存函数开销有了进一步下降,同时也不再有明显的 GC。
兼容性

其他优化方向
DOM 操作
Performance 性能面板同样指出,这个问题同时也伴随着布局移动(Layout Shift),也会造成渲染卡顿,不过此处该问题影响不明显,故不做修正。
ServiceWorker
另一种思路是,将重查询的逻辑移植到 Web Worker 中,利用浏览器多线程的能力,避免重查询函数的运行阻塞主线程,从而导致渲染卡顿。
小结
此类问题由于前端数据量较大时,函数执行的时间往往存在非线性乃至指数级增长,其根本问题通常是前端处理不当导致函数复杂度不合理增加,可以通过增加缓存和算法优化来修复;
另一种方案往往是选择在后端乃至数据库层面处理此类数据,由异步请求与前端通信,可以更好的利用服务器性能,同时也避免对前端页面产生渲染开销。